minkwe wrote:Seriously!? Do you have some kind of memory loss syndrome or something. Please flip back 10 pages and start reading. YOU ARE REPEATING DEBUNKED ARGUMENTS!!!
Making your bald pronouncements ALL CAPS does not make them any more true. One usually uses arguments for that purpose.
minkwe wrote:but you continue to disagree with it. The only remaining question is under what circumstances can we apply the inequality derived in point (1), to the independent sets from point (3). Again, I have to repeat this because it appears you need repetition to follow simple arguments. A 4xN spreadsheet of
outcomes , \; i \to N)
, implies the CHSH (ie
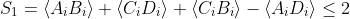
) STOP trying to convince us of this fact which has never been contested. In fact, this is the only requirement necessary to obtain the CHSH, the presence of a 4xN spreadsheet of
outcomes! It is a mathematical tautology, nothing can violate it, not even QM.
But QM does never produce the 4xN spreadsheet, at least not with all values filled; instead, it produces something that can be ordered into the table I gave above. And, as it happens, there exists no way to 'complete' this table: every single way of adding values will inexorably lead to a decrease of the correlations below the CHSH bound. This, and this alone, is the essence of Bell's theorem.
minkwe wrote:4 independent sets of pairs of
outcomes does not produce a 4xN spreadsheet. It produces 4 separate independent 2xN spreadsheet of outcomes
 , (C_k, D_k), (A_i, B_i), (A_l, D_l))
which implies
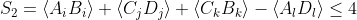
. It does not matter if you stack them on top of each other, you do not get a 4xN spreadsheet.
No, I get a 4x4N spreadsheet, for which the CHSH inequality holds if it can be filled up with additional values. In particular, the CHSH inequality will also hold for all the four sub-lists you describe, if they can be completed. But, and this is the crucial point: for QM, the 4x4N spreadsheet can't be completed; hence, there exists no LHV theory completing it.
minkwe wrote:The point you still do not get is that the inequality derived from a FULL 4xN spreadsheet does not apply to your stacked 4xN spreadsheet with empty spaces.
I get that perfectly well: that's after all how QM violates the CHSH inequality, while no LHV model can. For the LHV model, it is always possible to find some completion of the table; for QM, it isn't (in certain cases).
The only remaining question is: what conditions need to apply in order for the inequality derived for 4xN spreadsheet of outcomes, to apply to 4 independent 2xN spreadsheets of outcomes.[/b]
The condition is the same as always: there must exist a LHV model. Then, each of the 4 independent spreadsheets can be completed, i.e. have values assigned for the unmeasured observables, and the CHSH inequality holds.
In other words, if those conditions are not met, it would be wrong to conclude that
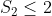
. When I asked you for the QM predictions for the terms in
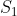
ie

, you gave me QM predictions for
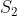
ie

, claiming that you are allowed to do this because the terms are equivalent. This is point (4) which you agree with.
Again, this is trivial if you perform measurements on the same state (well, sufficiently many copies of particles in the same state, to be accurate).
minkwe wrote:And if those rearrangements can be made, then the inequality
follows, even for QM! But point 8 shows that those conditions are impossible to meet.
I've shown you how these conditions can be met: if and only if there is a LHV model, you have a joint PD, and hence, can complete the spreadsheets, and rearrange them as desired. This fails for QM, because there, you don't have a LHV model. What's so difficult about that?
minkwe wrote:Therefore it is wrong to conclude that the QM predictions for
are the same as the QM predictions for
like you did. Similarly, it is wrong to conclude that the
inequality applies to
.
These are different things: the QM predictions are the same because you carry out experiments on the same state. The LHV bound obtains if you have a LHV model in each case (since again, then you can do your rearrangement).
minkwe wrote:Duh! If a joint PD of outcomes (4xN spreadsheet) exists, the CHSH
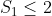
follows immediately.
Exactly! And what I've shown is that you can do your rearrangements exactly if such a joint PD exists, and thus, if you have a LHV model, you can rearrange; if you don't have one, you obviously can't, and hence, the CHSH bound does not apply---but this is just a different way of saying that correlations which violate the CHSH inequality have no explanation in terms of LHVs.
minkwe wrote:The only remaining question is under what conditions can we reduce 4 separate independent 2xN spreadsheets of outcomes into a single 4xN spreadsheet. Point 8 shows that this cannot be done. Therefore you are wrong to conclude that for LHV theories, it can always be done.
But I've given an explicit recipe to do it in this case! This is a bit frustrating, to be honest.
minkwe wrote:Your confusion arises because you think these 4 2xN spreadsheets which were generated by combining paired columns from our original 4xN spreadsheet, are the same as 4 independent 2xN spreadsheets. You are woefully wrong here. The 2xN spreadsheets in point (2) are not independent. Those in point (3) are independent.
OK, define your use of 'independent'. I mean, of course you can make measurements on four separate systems such that for the first system, you get out the QM correlation prediction for A and B, for the second, the prediction for B and C, and so on, or even exceed them, yielding a value of 4; but of course, we're here talking about measurements on the same system (or again, sufficiently many copies thereof). And again, for each of the four systems, were you to measure the other observables, you'd find the CHSH inequality satisfied if there exists an LHV model.
So OK, maybe I can make sense of what you're saying in this way: you obtain your four different lists by measurements on what may not be the same system in all cases; then, of course, there is no bound for the CHSH quantity except the algebraic one. But of course, this only works if whenever say A and B are measured, the (LHV-) system that yields the appropriate correlation to violate the CHSH inequality is present, and if B and C are measured, then the system that yields the appropriate correlation for those is present, and so on, since no single LHV-system exists that can yield the appropriate correlation for all terms, which you now seem to agree on---such a system always yields a full table. But this of course can't be the case in actual Bell tests, since there, it is randomly decided which measurement will be made after the system has already been prepared, so there is no way to ensure that always the system yielding the appropriate correlations is produced. The best the source could do is select between those systems randomly, which however would never lead to a violation of the CHSH inequality.
It bears repeating one more time. The only question remaining is under what conditions are the 4 2xN spreadsheets from point (2), which are not independent from each other, statistically equivalent to the 4 independent 2xN spreadsheets from point (3), as you claim they are in point (4). Point (8) shows that those conditions are impossible. Therefore point (4), which is your claim, is false and the QM predictions are not the same for the two scenarios, and the inequalities are not the same for the two scenarios.
I suppose it then bears repeating one more time, too that the QM predictions are the same if in all four 2xN tables, you have performed measurements on copies of singlet states, and the rearranging is possible exactly if you have a hidden variable model applying to all four cases.
minkwe wrote:If I toss a die such that it settles with the 5 exposed sides facing up(U), north(N), south(S), east(E) and west(W). I ask two experimenters (Alice and Bob) to pick a direction from the exposed sides to observe and the outcomes which we will denote as (A) and (B) respectively, one after the other. Let us suppose that the act of reading the die destroys the chosen face and makes it unavailable for the second experimenter to observe the same face. Once a direction is picked, say N, the remaining experimenter can only pick one of the remaining 4 directions U, S, E, W.
Again, that's disanalogous to the situation in Bell test experiments: nothing one experimenter does can in any way impinge on what the other one does, because in this case, we have a failure of locality.
minkwe wrote:We can repeat this procedure using just the T-reading device and still verify the same relationship holding exactly P(H) + P(T) = 1. But what if we toss our identical types of coins N times into the H-reading device, and from that calculate just P(H), and N times into the T reading device and from that calculate just P(T)? But it would be quite naive to think that the relationship P(H) + P(T) = 1 continues to hold. In fact, such a scenario can violate the relationship drastically, up to P(H) + P(T) = 2.
Only if you assume that your 'identical' coins don't in fact have the same probability distribution. In which case, yes, you could violate the inequality, by say having two types of coins, one for which P(H) is approximately one (and hence, P(T) is approximately 0), and the other for which P(T) is approximately one, and P(H) approximately zero. But you'd have to make sure only to throw the first kind of coin into the H-reading device, and the second kind of coin into the T-reading device; in a Bell test, however, the nature of the device will only be decided once the coin is already in the air, and it's not hard to see that in this case, always P(T) + P(H) = 1 (at least up to statistical error): simply because on average, each type of coin lands as often in a H-measuring device as in a T-measuring device, these measurements simply tell us, for that type of coin, the actual probabilities with which the coin lands heads or tails. Thus, for each type of coin, we have that P(H) + P(T) = 1. Hence, if a fraction x of the coins have one probability distribution with P(H) = pxH and P(T) = pxT, and a fraction y of the coins have a probability distribution with P(H) = pyH and P(T) = pyT, then x*(pxH + pxT) + y*(pyH + pyT) = (x+y)*1 = 1, since x + y is the total fraction of coins.

, since those are the terms in the CHSH inequality.
