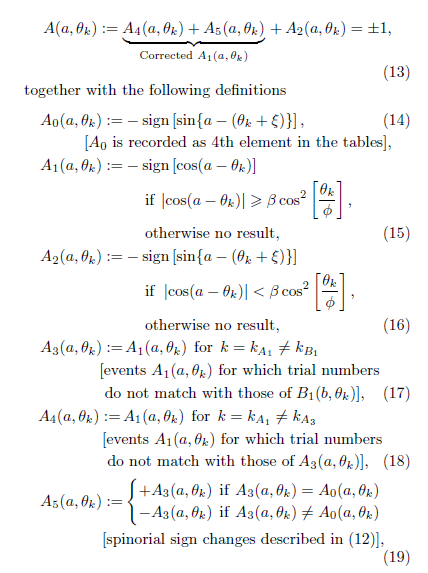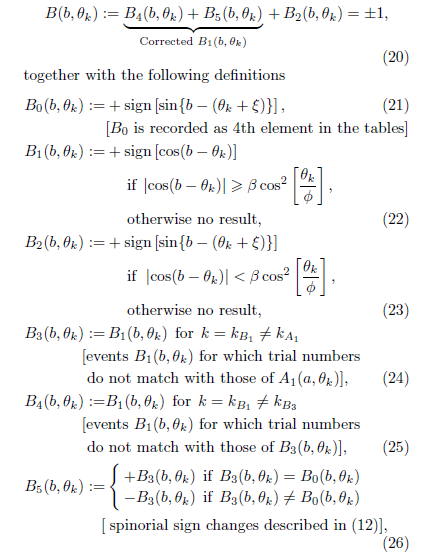Guest wrote:gill1109 wrote:When I do my test I’ll find that at least 20% of the trials have been ‘fixed’ in a non-local way. Of course, my definition of local and non-local is not Fred’s definition. Fred hasn’t even told us his definition. So we’ll never agree. Too bad. Fred and Joy will publish their paper and the younger among us will be able to observe what the world of physics makes of it.
Hi Rick! Is there a known universal (distribution free) lower bound for the rate of "no show" events in this kind of pearlesque models which reproduce the QM correlations?
I hope you're in better shape.
Best,
Guest.
Hi “Guest”, I’m fine! Just turned 70, cycled 60 Km yesterday.
Yes, there is a lower bound. Here’s how you could guess what it might be.
With communication between the two sides of the experiment you could achieve S = 4.0
Bell-CHSH says that without communication you can’t exceed S = 2.0
Spooky quantum entanglement could give S = 2 sqrt 2 = 2.8 approx, needs to be operating on all trials.
Suppose you let Alice and Bob communicate on a fraction p of the trials.
They could then achieve S = 4 p + 2 (1 - p) = 2 + 2 p
So you will need 2 p = 0.8 in order to get 2.8.
p = 0.4
They need to change outcomes, using communication, on 40% of the trials.
That could be 20% of Alice’s outcomes and a different 20% of Bob’s outcomes.
There is a really good recent paper on this by Pavel Blasiak and others, published this year in PNAS.
https://arxiv.org/pdf/2105.09037.pdf“Violations of locality and free choice are equivalent resources in Bell experiments”
Pawel Blasiak, Emmanuel M. Pothos, James M. Yearsley, Christoph Gallus, and Ewa Borsuk
Of course, getting S = 2 sqrt 2 just fixes the quantum correlations at four pairs of angles. What if you want to fix them at all pairs of angles?
The Pearlesque thing using the detection loophole loses at least 20% of the trials. If you would keep them but replace lost particles by a detection value “0” you would reduce the amplitude of the negative cosine. Replacing “0” by a completely random bit +/-1 is just the same. It is indeed known that in order to generate - (1 - p) cos theta for *all* theta simultaneously with the detection loophole, theta has to be at least this same 20%.
I think this is all connected which is why I’m interested in Fred’s model. I just wish he’d write some short pseudo-code of his complete algorithm. This talk of matching k_A and k_B is “freakin’ nonsense” to use one of his favourite phrases, he’s already admitted that the outcomes from each trial are determined only by the settings and the hidden variable of the same trial. As he says, there are no “no show events” in his model.
Actually, John Reed has simple Mathematica code which reproduces Fred’s outcomes *exactly*. I must use it to compute the proportion of “fixed” trials (fixed by communication).
It’s very interesting that Fred has only one hidden variable per trial. Pearle has two!
It’s also curious that Fred uses formulas taken from Michel Fodje’s detection loophole model, rather than Pearle’s. Fodje gets approximately the negative cosine, Pearle gets it exactly, and moreover uniquely within a certain big class of detection loophole models.

=(-1)^{\delta}\,{\mathbf q}(\eta_{{\mathbf s}{\mathbf n}},\,{\mathbf r})\;\;\text{for}\;\delta=0,1,2,3,\dots)
=\,-\,{\mathbf q}(\eta_{{\mathbf s}{\mathbf n}},\,{\mathbf r}))
=\,\,{\mathbf q}(\eta_{{\mathbf s}{\mathbf n}},\,{\mathbf r}))